






As discussed in this blog post about half the weights in the HBF are zero which contribute nothing to the filter output and should be ignored. An odd-length N half band filter was partitioned into branches ![h_{A}[n]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-a195f7d8ee877c2a0a19bed3d5149bed_l3.png "Rendered by QuickLaTeX.com") and
and ![h_{b}[n]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-3467826894741b0d61a1a7050376e9f4_l3.png "Rendered by QuickLaTeX.com") , an example given in Figure 1.
, an example given in Figure 1.
![Figure 1: The weights of the partitioned half band filter hA[n] and hB[n].](https://www.wavewalkerdsp.com/wp-content/uploads/2021/09/halfBandFilterPolyphase_HBFImpulseResponsePolyphasePartition-1-1024x614.png)
The branch ![h_{B}[n]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-a70ebfce687764550ee7465db92b3239_l3.png "Rendered by QuickLaTeX.com") is mostly zeros except for time index
is mostly zeros except for time index
(1) 
and therefore can be simplified as
(2) ![\begin{equation*}h_{B}[M] \neq 0,\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-69098318cd4b7e3a59d7452f56558079_l3.png "Rendered by QuickLaTeX.com")
(3) ![\begin{equation*}h_{B}[n] = 0 ~ \text{for} ~ n \neq M.\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-8d01618d55fcbcc7147c0a488fc50519_l3.png "Rendered by QuickLaTeX.com")
The impulse response can be simplified to
(4) ![\begin{equation*}z^{-M} \cdot h_{B}[M]\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-dc34a2e00a2bb50ced3865430e63880d_l3.png "Rendered by QuickLaTeX.com")
which is just a delayed single weight as shown in Figure 2.
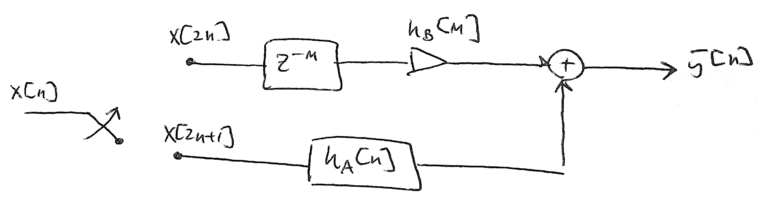
As shown previously the weights of are even-symmetric such that
(5) ![\begin{equation*}h_{A}[n] = h_{A}\left[\frac{N-1}{2}-n\right]\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-37fe70e698ac414957e764e39e67b100_l3.png "Rendered by QuickLaTeX.com")
for  . Therefore the filter weights for the branch represented by can be folded to remove redundant multiplications [lyons2011, p.493, p.702] as shown in Figure 4.
. Therefore the filter weights for the branch represented by can be folded to remove redundant multiplications [lyons2011, p.493, p.702] as shown in Figure 4.
![Figure 4: The PFB half band filter structure after folding the even-symmetric filter weights hA[n] and ignoring the zero weights in hB[n].](https://www.wavewalkerdsp.com/wp-content/uploads/2021/10/polyphaseHalfBandFoldedNoZeroMultiply-768x579.png)
Folding the even-symmetric filter weights reduces the number of multiplications by performing an extra addition of the data beforehand. As an example, without folding the filter branch would be implemented as
(6) ![\begin{equation*}x[2n+1]h_{A}[0] ~+~ x[2n+3]h_{A}[1] ~+~ x[2n+5]h_{A}[2] ~+~ x[2n+7]h_{A}[3] ~+~ x[2n+9]h_{A}[4] ~+~ x[2n+11]h_{A}[5]\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-9919826f69921d3bdf5e75bbadeca12a_l3.png "Rendered by QuickLaTeX.com")
which multiplies each input sample in the delay line with the corresponding filter weight. In this example ![h_{A}[0] = h_{A}[5]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-1bdeea5a8e2d1b42b9c1ccb7b2ae5aa5_l3.png "Rendered by QuickLaTeX.com") ,
, ![h_{A}[1] = h_{A}[4]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-46771add171c5258597521298ee0785c_l3.png "Rendered by QuickLaTeX.com") and
and ![h_{A}[2] = h_{A}[3]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-8bb78f4c071f48038b76e42eede86e65_l3.png "Rendered by QuickLaTeX.com") . Folding and performing a pre-addition reduces the implementation to
. Folding and performing a pre-addition reduces the implementation to
(7) ![\begin{equation*}\Big( (x[2n+1] + x[2n+11]) \cdot h_{A}[0] \Big) + \Big( (x[2n+3] + x[2n+9]) \cdot h_{A}[1] \Big) + \Big( (x[2n+5] + x[2n+7]) \cdot h_{A}[2] \Big).\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-9c5f74f18f614312087dbd830fea23a5_l3.png "Rendered by QuickLaTeX.com")
The code to implement the folded PFB in Figure 4 is given below:
## implement folded branch for hA[n]
# start with zeroed delay line
delayLine = np.zeros(len(AWeights))
# zero-pad the input so all input samples to the sample
# buffer are filtered
xAPad = np.concatenate((xA,np.zeros(len(AWeights)-1)))
# pre-allocate output
foldedAOutput = np.zeros(len(xAPad))
for index in range(len(xAPad)):
# add in new sample to delay line
delayLine = np.insert(delayLine,0,xAPad[index])
# remove the last sample from the delay line
delayLine = delayLine[0:-1]
# perform the pre-add
preAdd = delayLine[0:M] + delayLine[-1:-M-1:-1]
# multiply weights
weightedPreAdd = preAdd*AWeights[0:M]
# summation
foldedAOutput[index] = np.sum(weightedPreAdd)
# folded PFB output
yPolyParallelFolded = foldedAOutput + BOutput
Figure 5 gives an example of the output from the folded PFB with ignored zero weights showing it is the same output as the naive decimation approach.
It was shown prior that applying a PFB structure to a decimate by 2 for filter length N can reduce the amount of multiplies by 1/2. The efficiencies from ignoring the zero weights in as well as folding the even-symmetric weights in will further reduce the number of multiplies needed to implement the filtering.
Ignoring the zero weights in leads to a single multiply for in the branch where there are  multiples in the branch in Figure 2. The number of multiplies per output sample is therefore
multiples in the branch in Figure 2. The number of multiplies per output sample is therefore
(8) 
As the decimation by 2 PFB structure has already been applied it therefore only takes
(9) 
multiplies per each input sample which is 4 times as efficient than the naive implementation! The benefit of the PFB approach is that the filtering can be done at the decimated output sample rate as seen here.
For example a half band filter with length N=19 the subfilter corresponding to can be implemented with a single multiply and implemented with  for a total of 10 multiples per output sample. However due to the PFB structure the number of multiplies per input sample is 10/2 = 5.
for a total of 10 multiples per output sample. However due to the PFB structure the number of multiplies per input sample is 10/2 = 5.
Additional savings come from folding the even-symmetric weights in . The filter branch has  weights however half of them are even-symmetric and the number of multiplies can be reduced through a pre-add as in Figure 4. The number of multiplies for an output sample for the branch is therefore
weights however half of them are even-symmetric and the number of multiplies can be reduced through a pre-add as in Figure 4. The number of multiplies for an output sample for the branch is therefore
(10) 
Adding one multiply for the branch to (10), the total number of multiplies per output sample for a half band folded PFB with ignored zero weights is therefore
(11) 
For example a filter of length N=19 the filter is implemented with  multiplies.
multiplies.
However the PFB structure allows the filter to run at the output sample rate which is 1/2 the input sample rate, therefore the number of multiples per input sample is
(12) 
which is 8 times more efficient than the naive decimator!
Improving the efficiency by a factor of 8 is a huge savings! In dB that is  dB. It’s not everyday you find a free 9 dB worth of efficiency to be gained in your system through rearranging some delays, multiplies and adds.
dB. It’s not everyday you find a free 9 dB worth of efficiency to be gained in your system through rearranging some delays, multiplies and adds.
2 Responses
The Homer reference was chefs kiss ?
I knew you would like it!
You can check out Joe Gaeddert’s work at https://liquidsdr.org and get his Liquid DSP software on github at https://github.com/jgaeddert/liquid-dsp