
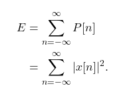




![Figure 1: A naive implementation of decimation by 2: low-pass filtering with h[n] followed by downsampling by 2.](https://www.wavewalkerdsp.com/wp-content/uploads/2021/09/LPFThenDownsample.png)
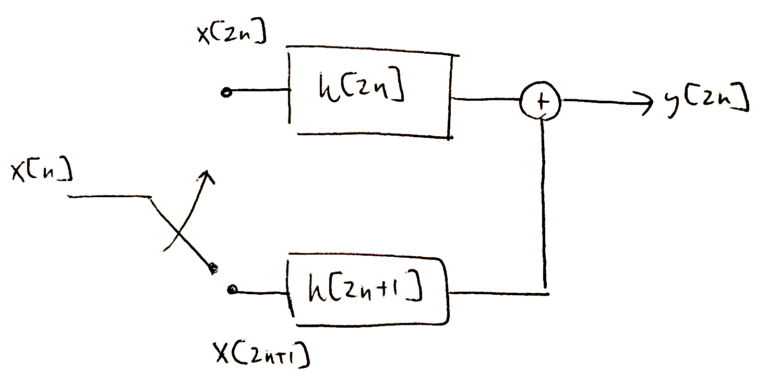
![Figure 2: The downsampling by 2 process keeps all even index time samples and discards all odd index time samples, wasting the computation from h[n].](https://www.wavewalkerdsp.com/wp-content/uploads/2021/09/LPFWithDiscard-768x132.png)
The filter output is written as
(1) ![\begin{equation*}y[n] = \sum_{k} x[n-k] h[k],\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-6cfe07bc310a2793d46f3c28194fa082_l3.png "Rendered by QuickLaTeX.com")
which is then downsampled by 2
(2) ![\begin{equation*}y[2n] = \sum_{k} x[2n-k] h[k].\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-13eb2f87e979bf48bc316c92950faa17_l3.png "Rendered by QuickLaTeX.com")
Rearranging the filtering operation into even values of k and odd values of k,
(3) ![\begin{equation*}y[2n] = \sum_{k ~\text{even}} x[2n-k] h[k] + \sum_{k ~\text{odd}} x[2n-k] h[k],\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-69d1e03242a7710e17396301d67f6603_l3.png "Rendered by QuickLaTeX.com")
is the first step towards turning the filter h[n] into a two-path or two-branch polyphase filterbank according to even time index and odd time index samples. The  summation can be written as
summation can be written as
(4) ![\begin{equation*}\sum_{k} x[2n-2k] h[2k]\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-c507d295390d0c8066fb41a180025db6_l3.png "Rendered by QuickLaTeX.com")
and then  as
as
(5) ![\begin{equation*}\sum_{k} x[2n-2k-1] h[2k+1],\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-0849ee25bb8c9ca69624914e4d58ea55_l3.png "Rendered by QuickLaTeX.com")
such that the downsampled output is
(6) ![\begin{equation*}y[2n] = \sum_{k} x[2n-2k] h[2k] + \sum_{k} x[2n-2k-1] h[2k+1],\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-12244e296bc89097f99300377613512b_l3.png "Rendered by QuickLaTeX.com")
(7) ![\begin{equation*}y[2n] = \sum_{k} x[2(n-k)] h[2k] + x[2(n-k)-1] h[2k+1].\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-599b0bca24b431593d988df6d0db7185_l3.png "Rendered by QuickLaTeX.com")
The even filter weights are one branch, applied to the even time index input samples
(8) ![\begin{equation*}\sum_{k} x[2(n-k)] h[2k]\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-d2ad615edab86a834b626ab779c1971c_l3.png "Rendered by QuickLaTeX.com")
where the odd filter weights are the second branch, applied to the odd time index input samples
(9) ![\begin{equation*}\sum_{k} x[2(n-k)-1] h[2k+1].\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-cc731dbce3e96871fbbe75a172da7401_l3.png "Rendered by QuickLaTeX.com")
![Figure 5: The impulse response of the HBF weights h[n].](https://www.wavewalkerdsp.com/wp-content/uploads/2021/09/halfBandFilterPolyphase_HBFImpulseResponse.png)
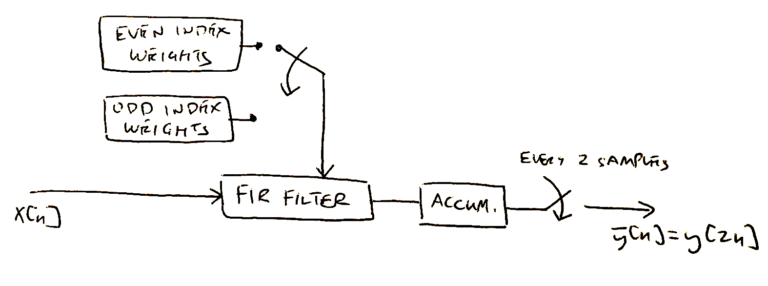
Figure 3 shows that the parallel polyphase filterbank structure has two sub-filters for even and odd indexed weights. It makes writing the software easier (with marginal computational cost) if the two sub-filters are of equal length. Yet the impulse response in Figure 3 is odd-length so it must be zero-padded by 1 sample to make it even length. At first glance it would seem that the zero-padding should occur at the end of the impulse response but is that the correct choice?
Consider that convolution performs a time reversal therefore zero-padding the tail of h[n] with 1 sample will in effect turn add a 1 sample delay to the input which is undesired. Instead a 1 sample zero-pad needs to be added to the beginning of h[n] because the zero-padding ends up being at the end of the time-reversed weights and therefore has no impact on the convolution. The padded h[n] will therefore be ![\tilde{h}[n]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-a769f6f2aa4bd0a1b3549f841208acf9_l3.png "Rendered by QuickLaTeX.com") such that
such that
(10) ![\begin{equation*}\tilde{h[n]} = h[n-1].\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-b6ad81797b2991be2ed242655437c6fe_l3.png "Rendered by QuickLaTeX.com")
The code to zero-pad the impulse response is as follows:
HBFWeightsPad = np.concatenate((np.zeros(1),HBFWeights))
Figure 6 gives the impulse response for h[n] and zero-padded .
![Figure 6: The impulse response for h[n] and the zero-padded tilde(h)[n].](https://www.wavewalkerdsp.com/wp-content/uploads/2021/09/halfBandFilterPolyphase_HBFImpulseResponsePadded-768x461.png)
The filter weights must be partitioned into two branches as in (8) and (9) however the even and odd phrasing will be replaced with filter branch A and B to avoid future confusion. The sub-filter ![h_{A}[n]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-a195f7d8ee877c2a0a19bed3d5149bed_l3.png "Rendered by QuickLaTeX.com") and
and ![h_{B}[n]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-a70ebfce687764550ee7465db92b3239_l3.png "Rendered by QuickLaTeX.com") are therefore defined as
are therefore defined as
(11) ![\begin{equation*}h_{A}[n] = \tilde{h}[2n],\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-24af01abb974deb6bba494b2ba713752_l3.png "Rendered by QuickLaTeX.com")
(12) ![\begin{equation*}h_{B}[n] = \tilde{h}[2n+1].\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-d0496d655a3fb3acf539831c6a9b6fba_l3.png "Rendered by QuickLaTeX.com")
The code to perform the partioning is given below:
AIndices = np.arange(1,len(HBFWeightsPad),2)
AWeights = HBFWeightsPad[AIndices]
BIndices = np.arange(0,len(HBFWeightsPad),2)
BWeights = HBFWeightsPad[BIndices]
The AIndices variable starts at an index of 1 due to the 1 sample delay of (10). This 1 sample delay turns even indices odd and odd indices even which is incredibly confusing and why the labels A and B are used instead. Example impulse responses of and are given in Figure 7.
![Figure 1: The weights of the partitioned half band filter hA[n] and hB[n].](https://www.wavewalkerdsp.com/wp-content/uploads/2021/09/halfBandFilterPolyphase_HBFImpulseResponsePolyphasePartition-1-768x461.png)
The input x[n] is downampled into ![x_{A}[n]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-d906d62683104cd78dbe957634aa3d76_l3.png "Rendered by QuickLaTeX.com") and
and ![x_{B}[n]](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-1e9899f693a1cfb5263620edba98641e_l3.png "Rendered by QuickLaTeX.com") as in (8) and (9) such that
as in (8) and (9) such that
(13) ![\begin{equation*}x_{A}[n] = x[2n],\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-0935e5cefcc838ed58a924542f80269b_l3.png "Rendered by QuickLaTeX.com")
(14) ![\begin{equation*}x_{B}[n] = x[2n+1].\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-7a9c13bea4cae6d3114fbb70bd972e0a_l3.png "Rendered by QuickLaTeX.com")
The code to downsample the input is given by:
xA = x[0::2]
xB = x[1::2]
The last step is to put all of the parts together. The polyphase filterbank output is the summation of the convolution of the two branches,
(15) ![\begin{equation*}\bar{y}[n] = \left(x_{A}[n] \ast h_{A}[n]\right) + \left(x_{B}[n] \ast h_{B}[n]\right).\end{equation*}](https://www.wavewalkerdsp.com/wp-content/ql-cache/quicklatex.com-fc25629cb14210899ad3186bc7a455ab_l3.png "Rendered by QuickLaTeX.com")
The code to implement the parallel polyphase filterbank is as follows:
AOutput = np.convolve(AWeights,xA)
BOutput = np.convolve(BWeights,xB)
yPolyParallel = AOutput + BOutput
Figure 8 demonstrates the equivalence of the naive decimation from Figure 1 with the polyphase filterbank in Figure 3 by plotting the two outputs after filtering a randomized input signal.
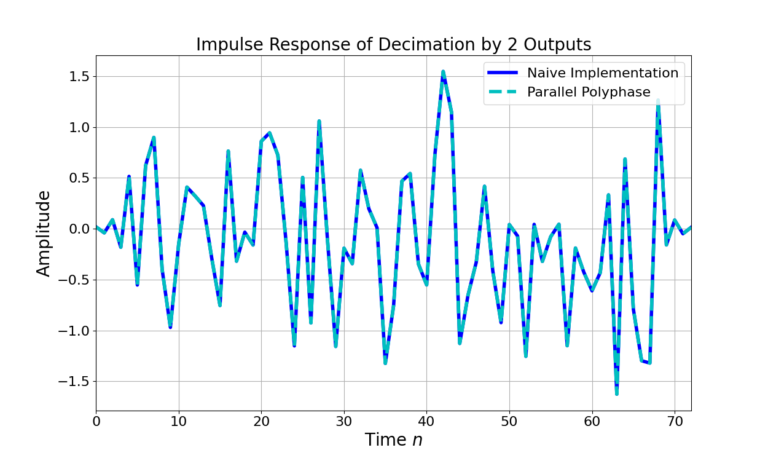
The naive implementation in Figure 1 requires N multiples for each input sample to implement a FIR filter of length N. However the polyphase implementation requires only N multiplies for every 2 input samples, which is 1/2 the work of the naive implementation. Thinking about the performance gain in dB, implementing the decimation saves  which is a great improvement for simply rearranging some filtering.
which is a great improvement for simply rearranging some filtering.
Additional savings can be obtained through ignoring the zero weights in sub-filter as well as folding the even-symmetric weights in sub-filter . Both of these filter structures will be covered in a future blog post.